
Open your favorite social media platform and note how many friends or followers you have. Specifically, note the first digit of this number. For example, if you have 400 friends, the leading digit is 4, and if you have 79, it’s 7. Let’s say we asked many people to do this. We might expect responses across the board, as common intuition suggests that friend counts should be somewhat random and therefore their leading digits should be too, treating 1 through 9 equally. Strangely, this is not what we would find. Instead, we would see a steep imbalance where nearly half of people have friend counts beginning with 1 or 2, while a paltry 10 percent begin with 8 or 9. Remember, this isn’t about having more or fewer friends: having 1,000 friends is way more than having eight.
This bizarre overrepresentation of 1s and 2s extends beyond friends and followers to likes and retweets, and well beyond social media to countless corners of the numerical world: country populations, river lengths, mountain heights, death rates, stock prices, even the diverse collection of numbers found in a typical issue of Scientific American. Not only are smaller leading digits more common, but they follow a precise and consistent pattern.
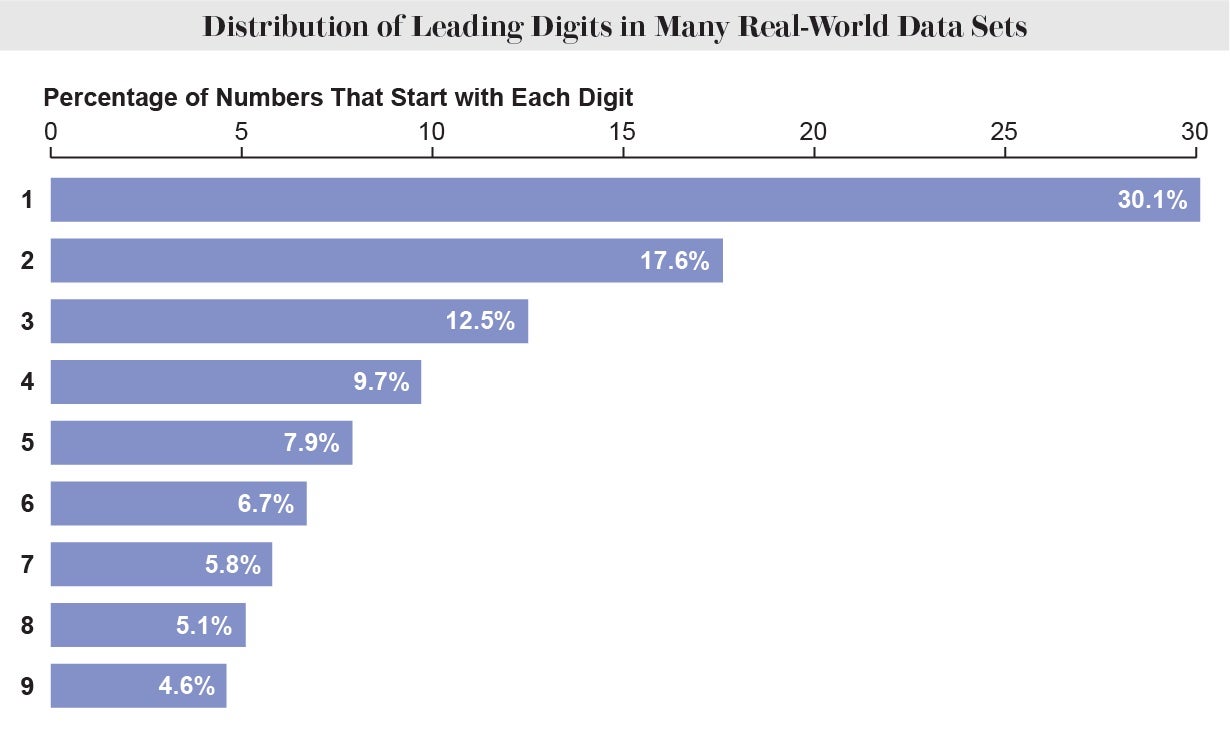
If all digits were represented equally, as one would naively expect, then they would each appear one ninth (about 11.1 percent) of the time. Yet, in an uncanny number of real-world data sets, an astonishing 30.1 percent of the entries begin with a 1, 17.6 percent begin with a 2, and so on. This phenomenon is known as Benford’s law. The law even persists when you change the units of your data. Measure rivers in feet or furlongs, measure stock prices in dollars or dinars, any way you measure, these exact proportions of leading digits persevere. While mathematicians have proposed several clever reasons for why the pattern might emerge, its sheer ubiquity evades a simple explanation.
It may seem like a mild observation, but Benford’s law has been used to powerful effect to put people behind bars and detect massive operations of fraud.
Before calculators, people outsourced hairy arithmetic to reference books called logarithm tables. In 1881, astronomer Simon Newcomb noticed that early pages of logarithm tables, which correspond to numbers beginning with one, were grubby and worn compared with the pristine later pages. He deduced that smaller leading digits must be more common in natural data sets, and he published the correct percentages. Physicist Frank Benford made the same observation in 1938 and popularized the law, compiling more than 20,000 data points to demonstrate its universality. Digression: Benford’s eponymous credit is an instance of Stigler’s law, which contends that scientific discoveries are never named after their original discoverer. Stigler’s law was asserted by sociologist Robert K. Merton well before Stephen Stigler got his name on it.
Benford’s law is not merely a statistical oddity: financial advisor Wesley Rhodes was convicted of defrauding investors when prosecutors argued in court that his documents did not accord with the expected distribution of leading digits, and they were therefore likely fabricated. The principle later helped computer scientist Jennifer Golbeck uncover a Russian bot network on Twitter. She observed that for most users, the number of followers that their followers have adheres to Benford’s law, but artificial accounts significantly veer from the pattern. She used similar methods to catch people who purchase bogus retweets. Examples of Benford’s law applied to fraud detection abound, from Greece manipulating macroeconomic data in its application to join the eurozone to vote-rigging in Iran’s 2009 presidential election. The message is clear: organic processes generate numbers that favor small leading digits, whereas naive methods of falsifying data do not.
Why does nature produce a dearth of nines and a glut of ones? First, it’s important to state that many data sets do not conform to Benford’s law. Adult heights mostly begin with 4s, 5s and 6s when measured in feet. A roulette wheel is just as likely to land on a number beginning with 2 as with 1. The law is more likely to spring from data sets spanning several orders of magnitude that evolve from certain types of random processes.
Exponential growth is a particularly intuitive example. Imagine an island that is initially inhabited by 100 animals, whose population doubles every year: after one year, there are 200 animals, and after two years there are 400. Already we notice something curious about the leading digits. For the whole duration of the first year, the first digit of the population size of the island was a 1. On the other hand, in the second year population counts spanned the 200s and 300s for the same period, leaving less time for each leading digit to reign. This continues, with 400 to 800 in the third year, where the leading digits retire faster still. The idea is that to grow from 1,000 to 2,000 requires doubling, whereas growing from 8,000 to 9,000 is only a 12.5 percent increase, and this trend resets with each fresh order of magnitude. There is nothing special about the parameters we chose in the island example. We could begin with a population of 43 animals and grow by a factor of 1.3 per year, for example, and it would yield the same exact pattern of leading digits. Almost all exponential growth of this sort will tend toward Benford.
The law’s stubborn indifference toward units of measure gives another hint as to why the pattern is so common in the natural world. River lengths follow Benford's law whether we record them in meters or miles, whereas non-Benford-complying data like adult heights would radically change their distribution of leading digits when converted to meters, as nobody is four meters tall. (Remarkably, Benford’s is the only leading digit distribution that is immune to such unit changes.) We can think of changing units as multiplying every value in our data set by a certain number. For example, we would multiply a set of lengths by 1,609.34 to convert them from miles to meters. Benford’s law is actually resilient to a much more general transformation. Taking Benford-complying data and multiplying each entry by a different number (rather than a fixed one like 1,609.34) independent of the data, will leave the leading digit distribution unperturbed. This means that if a natural phenomenon arises from the product of several independent sources, then only one of those sources must accord with Benford’s law in order for the overall result to. Benford’s law is cannibalistic, much in the same way that if you multiply a bunch of numbers together, only one of them needs to be zero for the whole result to be zero.
These explanations account for many appearances of the pattern, but they don’t explain why the diverse collection of numbers plucked from an issue of Scientific American would exhibit Benford’s law: these numbers don’t grow exponentially, and we’re not multiplying them together. Mathematician Ted Hill discovered what many consider to be the definitive proof of the leading digit law. His argument is unfortunately quite technical, but in simplistic terms says that if you pick a bunch of random numbers from a bunch of random data sets (in math terms, probability distributions), then they will tend toward Benford’s law. In other words, while we’ve seen that countless data sets show Benford’s pattern, the most reliable way to achieve it is to pull numbers from varying sources, like those we see in a newspaper.
I have spent a lot of time thinking about Benford's law, and despite the tapestry of explanations, it still surprises me how often it occurs. Pay attention to the numbers you encounter in your daily life and you might begin to spot it.
This is an opinion and analysis article, and the views expressed by the author or authors are not necessarily those of Scientific American.
 Rights & Permissions
Rights & Permissions
